NumPy: 初心者のための絶対基礎
NumPy の初心者向けガイドへようこそ!
NumPy(Num erical Python)は、科学技術の分野で広く使われているオープンソースのPythonライブラリです。NumPyライブラリには、同次配列やN次元配列などの多次元配列データ構造と、 ndarrayこれらのデータ構造を効率的に操作する大規模な関数ライブラリが含まれています。NumPyの詳細については、 「NumPyとは」をご覧ください。ご意見やご提案がございましたら、お気軽 にお問い合わせください。
NumPyのインポート方法
NumPy をインストールしたら、次のように Python コードにインポートできます。
import numpy as np
この広く普及した規則により、NumPy 機能に短い認識可能なプレフィックス ( np.) を使用してアクセスし、NumPy 機能を同じ名前の他の機能と区別することができます。
サンプルコードを読む
NumPy のドキュメント全体にわたって、次のようなブロックが見つかります。
>>>または...で始まるテキストはinput、つまりスクリプトまたはPythonプロンプトに入力するコードです。それ以外のテキストはoutput、つまりコード実行結果です。ただし>>>、 と...はコードの一部ではなく、Pythonプロンプトで入力するとエラーが発生する可能性があることに注意してください。
例のコードを実行するには、コードをコピーして Python スクリプトまたは REPL に貼り付けるか、ドキュメントのさまざまな場所で提供されているブラウザーの実験的なインタラクティブな例を使用します。
NumPy を使う理由
Pythonのリストは優れた汎用コンテナです。「異種」、つまり様々な型の要素を格納でき、少数の要素に対して個別の操作を実行する際に非常に高速です。
データの特性や実行する必要がある操作の種類によっては、他のコンテナの方が適している場合があります。これらの特性を活用することで、速度を向上させ、メモリ消費量を削減し、様々な一般的な処理タスクを実行するための高水準な構文を提供できます。NumPyは、CPUで処理する大量の「同質」(同じ型)データがある場合に真価を発揮します。
「配列」とは何ですか?
コンピュータプログラミングにおいて、配列はデータの格納と取得のための構造体です。配列は、空間上のグリッドのように考えられ、各セルにデータの要素が1つ格納されます。例えば、データの各要素が数値である場合、「1次元」配列はリストのようにイメージできます。
2次元配列は、表のようなものです。
3次元配列は、まるで別々のページに印刷されたかのように積み重ねられた表のセットのようなものです。NumPyでは、この考え方が任意の次元数に一般化されているため、基本的な配列クラスは と呼ばれndarray、「N次元配列」を表します。
ほとんどのNumPy配列にはいくつかの制限があります。例えば:
-
配列のすべての要素は、同じデータ型でなければなりません。
-
一度作成された配列は、合計サイズを変更することはできません。
-
形状は「長方形」でなければならず、「ギザギザ」であってはなりません。例えば、2次元配列の各行は同じ数の列を持たなければなりません。
これらの条件が満たされると、NumPy はこれらの特性を利用して、より制約の少ないデータ構造よりも高速で、メモリ効率が高く、使いやすい配列を作成します。
この文書の残りの部分では、「配列」という言葉を のインスタンスを指すために使用しますndarray。
配列の基本
配列を初期化する方法の一つとして、リストなどのPythonシーケンスを使用する方法があります。例えば、次のようになります。
a = np.array([1, 2, 3, 4, 5, 6])
a
array([1, 2, 3, 4, 5, 6])
配列の要素には、さまざまな方法でアクセスできます。たとえば、元のリストの要素にアクセスするのと同じように、角括弧で囲んだ整数インデックスを使用して、この配列の個々の要素にアクセスできます。
a[0]
1
元のリストと同様に、配列も変更可能です。
a[0] = 10
a
array([10, 2, 3, 4, 5, 6])
元のリストと同様に、Pythonのスライス表記をインデックス付けに使用できます。
a[:3]
array([10, 2, 3])
大きな違いの一つは、リストのスライスインデックスでは要素が新しいリストにコピーされるのに対し、配列のスライスではビュー(元の配列のデータを参照するオブジェクト)が返されることです。元の配列はビューを使用して変更できます。
b = a[3:]
b
array([4, 5, 6])
b[0] = 40
a
array([ 10, 2, 3, 40, 5, 6])
配列操作でコピーではなくビューが返される場合について、より詳細な説明は「コピーとビュー」を参照してください。
2次元以上の配列は、ネストされたPythonシーケンスから初期化できます。
a = np.array(1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12)
a
array(1, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12)
NumPyでは、配列の次元を「軸」と呼ぶことがあります。この用語は、配列の次元と、配列が表すデータの次元を区別するのに役立ちます。例えば、配列はa4次元空間内の3つの点を表しているかもしれませんが、a「軸」は2つしかありません。
配列とリストのリストのもう1つの違いは、配列の要素には、各軸に沿ったインデックスを単一の角括弧で囲み、カンマで区切って指定することでアクセスできることです。たとえば、要素は8行1と列にあります3。
a[1, 3]
8
配列属性
このセクションでは 、配列の、、、およびndim属性についてshape説明sizeします。 dtype
配列の次元数はndim属性に含まれています。
a.ndim
2
配列の形状は、各次元に沿った要素数を指定する非負整数のタプルです。
a.shape
(3, 4)
len(a.shape) == a.ndim
True
配列内の要素の総数は固定されており、その値はsize 属性に含まれています。
a.size
12
import math
a.size == math.prod(a.shape)
True
配列は通常「同種」であり、つまり、単一の「データ型」の要素のみを含みます。データ型はdtype属性に記録されます。
a.dtype
dtype('int64') # "int" for integer, "64" for 64-bit
配列属性についてはこちら、 配列オブジェクトについてはこちらをご覧ください。
基本的な配列を作成する方法
このセクションでは 、、、、、np.zeros()についてnp.ones()説明 しますnp.empty()。np.arange()np.linspace()
要素のシーケンスから配列を作成する以外にも、0's で満たされた配列を簡単に作成できます。
np.zeros(2)
array([0., 0.])
1または、 'sで埋められた配列:
np.ones(2)
array([1., 1.])
あるいは空の配列でも構いません!この関数は、empty初期内容がランダムでメモリの状態に依存する配列を作成します。 (または類似のもの)emptyを使用する理由zerosは速度です。ただし、後で必ずすべての要素を埋めるようにしてください!
# Create an empty array with 2 elements
np.empty(2)
array([3.14, 42. ]) # may vary
要素の範囲を指定して配列を作成できます。
np.arange(4)
array([0, 1, 2, 3])
さらに、等間隔の区間を含む配列も指定できます。これを行うには、最初の数値、最後の数値、およびステップサイズを指定します。
np.arange(2, 9, 2)
array([2, 4, 6, 8])
np.linspace()また、指定した間隔で線形に配置された値を持つ配列を作成するためにも使用できます。
np.linspace(0, 10, num=5)
array([ 0. , 2.5, 5. , 7.5, 10. ])
データ型を指定する
デフォルトのデータ型は浮動小数点(np.float64)ですが、キーワードを使用して使用するデータ型を明示的に指定できますdtype。
x = np.ones(2, dtype=np.int64)
x
array([1, 1])
要素の追加、削除、並べ替え
このセクションでは np.sort()、np.concatenate()
配列のソートは を使えば簡単ですnp.sort()。関数を呼び出す際に、軸、種類、順序を指定できます。
この配列から始めるとします。
arr = np.array([2, 1, 5, 3, 7, 4, 6, 8])
以下の方法で、数値を昇順に素早く並べ替えることができます。
np.sort(arr)
array([1, 2, 3, 4, 5, 6, 7, 8])
配列のソート済みコピーを返す sort に加えて、以下の方法も使用できます。
-
argsortこれは、指定された軸に沿った間接的なソートです。 -
lexsortこれは、複数のキーに対する間接的な安定ソートです。 -
searchsortedソートされた配列内の要素を見つけ、 -
partitionこれは部分的なソートです。
配列のソートの詳細については、以下を参照してくださいsort。
これらの配列から始めるとします。
a = np.array([1, 2, 3, 4])
b = np.array([5, 6, 7, 8])
それらを連結することができますnp.concatenate()。
np.concatenate((a, b))
array([1, 2, 3, 4, 5, 6, 7, 8])
または、これらの配列から始める場合:
以下のように連結できます。
配列から要素を削除するには、インデックスを使用して残したい要素を選択するのが簡単です。
concatenate の詳細については、以下を参照してくださいconcatenate。
配列の形状とサイズはどのようにしてわかるのですか
このセクションでは ndarray.ndim、、、について説明しますndarray.size。ndarray.shape
ndarray.ndim配列の軸数、つまり次元数を示します。
ndarray.size配列の要素の総数が表示されます。これは、配列の形状を構成する要素の積です。
ndarray.shape配列の各次元に格納されている要素数を示す整数の組が表示されます。例えば、2行3列の2次元配列の場合、配列の形状は となります。(2, 3)
例えば、次のような配列を作成する場合:
配列の次元数を調べるには、以下を実行します。
array_example.ndim
3
配列内の要素の総数を調べるには、以下を実行します。
array_example.size
24
配列の形状を確認するには、以下を実行します。
array_example.shape
(3, 2, 4)
配列の形状を変更できますか
このセクションでは、 arr.reshape()
はい!
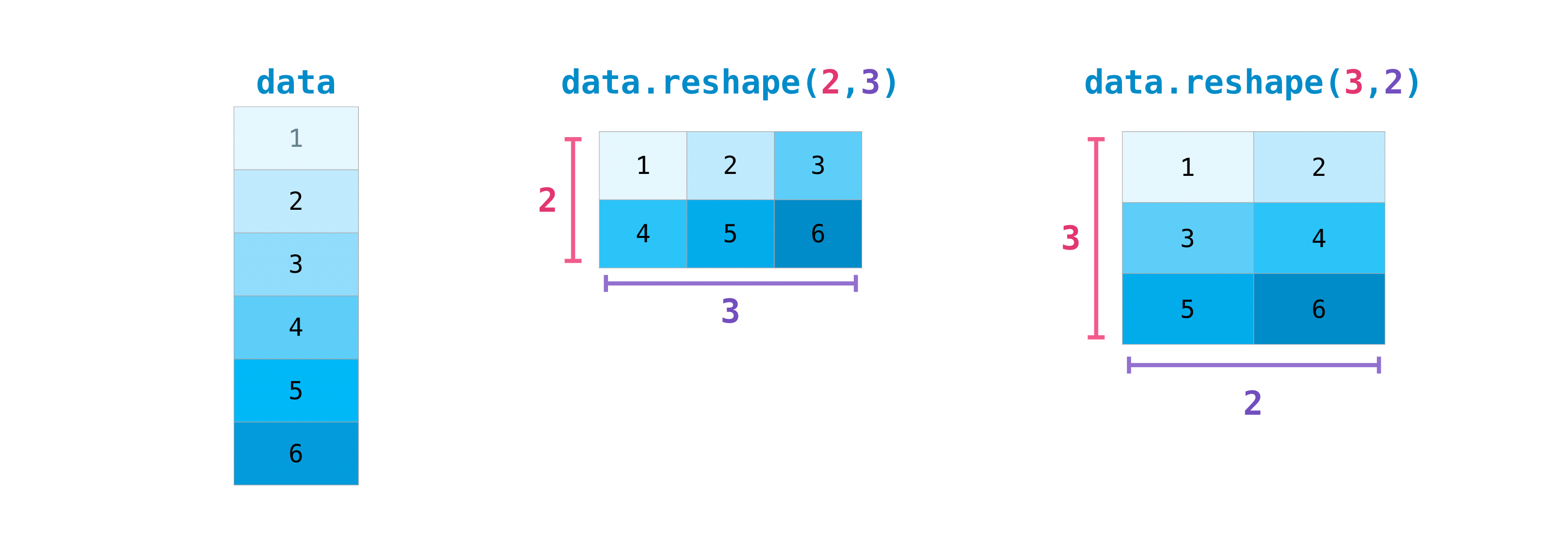
を使用するとarr.reshape()、データは変更されずに配列の形状が変更されます。reshapeメソッドを使用する場合、作成する配列の要素数は元の配列と同じである必要があることに注意してください。12個の要素を持つ配列から開始する場合、新しい配列の要素数も合計12個になるようにする必要があります。
この配列から始めるとします。
a = np.arange(6)
print(a)
[0 1 2 3 4 5]
配列の形状を変更するには、これを使用できますreshape()。たとえば、この配列を3行2列の配列に変更できます。
を使用するとnp.reshape、いくつかのオプションパラメータを指定できます。
aは、形状を変更する配列です。
shapeは、新しい形状を指定します。整数または整数のタプルを指定できます。整数を指定した場合、結果はその長さの配列になります。形状は元の形状と互換性がある必要があります。
order: Cは、C言語のようなインデックス順で要素を読み書きすることを意味し、 は、 FFortranのようなインデックス順で要素を読み書きすることを意味し、A は、aがメモリ内でFortranの連続した配列である場合はFortranのようなインデックス順で、そうでない場合はC言語のような順で要素を読み書きすることを意味します。(これはオプションのパラメータであり、指定する必要はありません。)
C と Fortran の順序について詳しく知りたい場合は、 NumPy 配列の内部構造についてこちらで詳しく読むことができます。基本的に、C と Fortran の順序は、インデックスがメモリに格納される配列の順序にどのように対応しているかに関係しています。Fortran では、メモリに格納されている 2 次元配列の要素を順に処理していくと、最初の インデックスが最も速く変化します。最初のインデックスが変化すると次の行に移動するため、行列は一度に 1 列ずつ格納されます。これが Fortran が列優先言語と呼ばれる理由です。一方、C では、最後のインデックスが最も速く変化します。行列は行ごとに格納されるため、行優先言語となります。C または Fortran でどのような処理を行うかは、インデックスの規則を維持することがより重要か、データの順序を変更しないことがより重要かによって異なります。
1次元配列を2次元配列に変換する方法(配列に新しい軸を追加する方法)
このセクションでは np.newaxis、np.expand_dims
np.newaxisと を使用して、np.expand_dims既存の配列の次元を増やすことができます。
を使用するnp.newaxisと、一度使用するごとに配列の次元が1つ増加します。つまり、1次元配列は2次元配列になり、 2次元配列は3次元配列になる、といった具合です。
例えば、次のような配列から始めるとします。
a = np.array([1, 2, 3, 4, 5, 6])
a.shape
(6,)
np.newaxis新しい軸を追加するには、以下を使用できます。
a2 = a[np.newaxis, :]
a2.shape
(1, 6)
1次元配列を明示的に行ベクトルまたは列ベクトルに変換するには、 を使用しますnp.newaxis。たとえば、最初の次元に沿って軸を挿入することで、1次元配列を行ベクトルに変換できます。
row_vector = a[np.newaxis, :]
row_vector.shape
(1, 6)
または、列ベクトルの場合、2次元目に沿って軸を挿入することもできます。
col_vector = a[:, np.newaxis]
col_vector.shape
(6, 1)
また、指定した位置に新しい軸を挿入することで配列を拡張することもできますnp.expand_dims。
例えば、次のような配列から始めるとします。
a = np.array([1, 2, 3, 4, 5, 6])
a.shape
(6,)
np.expand_dimsインデックス位置1に軸を追加するには、次のようにします。
b = np.expand_dims(a, axis=1)
b.shape
(6, 1)
インデックス位置0に軸を追加するには、次のようにします。
c = np.expand_dims(a, axis=0)
c.shape
(1, 6)
newaxisの詳細については、こちらと expand_dimsをご覧くださいexpand_dims。
インデックスとスライス
NumPy配列は、Pythonリストをスライスするのと同じ方法でインデックス付けやスライスを行うことができます。
data = np.array([1, 2, 3])
data[1]
2
data[0:2]
array([1, 2])
data[1:]
array([2, 3])
data[-2:]
array([2, 3])
次のようにイメージできます。

配列の一部または特定の配列要素を取り出し、さらなる分析や追加操作に使用したい場合があります。そのためには、配列のサブセット化、スライス、および/またはインデックス付けを行う必要があります。
配列の中から特定の条件を満たす値を選択したい場合、NumPyを使えば簡単にできます。
例えば、次のような配列から始めるとします。
配列内の5未満の値をすべて簡単に表示できます。
print(a[a < 5])
[1 2 3 4]
例えば、5以上の数値を選択し、その条件を使って配列のインデックスを作成することもできます。
five_up = (a >= 5)
print(a[five_up])
[ 5 6 7 8 9 10 11 12]
2で割り切れる要素を選択できます。
divisible_by_2 = a[a%2==0]
print(divisible_by_2)
[ 2 4 6 8 10 12]
&または、 and演算子を使用して2つの条件を満たす要素を選択することもできます| 。
c = a[(a > 2) & (a < 11)]
print(c)
[ 3 4 5 6 7 8 9 10]
論理演算子「&」と「|」を使用すると、配列内の値が特定の条件を満たすかどうかを示すブール値を返すことができます。これは、名前やその他のカテゴリ値を含む配列で役立ちます。
five_up = (a > 5) | (a == 5)
print(five_up)
False False False False]
[ True True True True]
[ True True True True
np.nonzero()配列から要素やインデックスを選択するためにも使用できます。
この配列から始めます。
np.nonzero()例えば、5未満の要素のインデックスを出力するには、次のようにします。
b = np.nonzero(a < 5)
print(b)
(array([0, 0, 0, 0]), array([0, 1, 2, 3]))
この例では、各次元に対応する配列のタプルが返されました。最初の配列は、これらの値が見つかった行インデックスを表し、2番目の配列は、これらの値が見つかった列インデックスを表します。
要素が存在する座標のリストを生成したい場合は、配列をzipし、座標のリストを反復処理して出力します。例:
list_of_coordinates= list(zip(b[0], b[1]))
for coord in list_of_coordinates:
print(coord)
(np.int64(0), np.int64(0))
(np.int64(0), np.int64(1))
(np.int64(0), np.int64(2))
(np.int64(0), np.int64(3))
np.nonzero()配列内の要素のうち、5未満のものを出力するには、以下の方法も使用できます。
print(a[b])
[1 2 3 4]
探している要素が配列内に存在しない場合、返されるインデックスの配列は空になります。例:
not_there = np.nonzero(a == 42)
print(not_there)
(array([], dtype=int64), array([], dtype=int64))
インデックス付けとスライスについての詳細は、こちら とこちらをご覧ください。
非ゼロ関数の使用方法については、以下を参照してくださいnonzero。
既存のデータから配列を作成する方法
このセクションでは 、、、、、、について説明します。 slicing and indexingnp.vstack()np.hstack()np.hsplit().view()copy()
既存の配列の一部から、簡単に新しい配列を作成できます。
仮に、次のような配列があるとしましょう。
a = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
配列のスライスする場所を指定することで、いつでも配列の一部から新しい配列を作成できます。
arr1 = a[3:8]
arr1
array([4, 5, 6, 7, 8])
ここでは、配列のインデックス位置3からインデックス位置8までの領域を取得しましたが、位置8自体は含まれていません。
注意:配列のインデックスは0から始まります。つまり、配列の最初の要素はインデックス0、2番目の要素はインデックス1、といった具合です。
既存の配列を縦方向にも横方向にも重ねることもできます。例えば、2つの配列があり、次のようになっているとしa1ますa2。
縦に積み重ねるには、以下の方法がありますvstack。
または、水平に積み重ねる場合hstack:
配列を複数の小さな配列に分割するには、 を使用しますhsplit。 を返す同じ形状の配列の数、または 分割を実行する列を指定できます。
仮に、次のような配列があるとしましょう。
x = np.arange(1, 25).reshape(2, 12)
x
array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24)
この配列を3つの同じ形状の配列に分割したい場合は、次のコマンドを実行します。
array(1, 2, 3, 4],
[13, 14, 15, 16), array(5, 6, 7, 8],
[17, 18, 19, 20), array(9, 10, 11, 12],
[21, 22, 23, 24np.hsplit(x, 3)
[)]
配列を3列目と4列目の後で分割したい場合は、次のように実行します。
array(1, 2, 3],
[13, 14, 15), array(4],
[16), array(5, 6, 7, 8, 9, 10, 11, 12],
[17, 18, 19, 20, 21, 22, 23, 24np.hsplit(x, (3, 4))
[)]
配列のスタッキングと分割について詳しくは、こちらをご覧ください。
このviewメソッドを使用すると、元の配列と同じデータを参照する新しい配列オブジェクト(シャローコピー)を作成できます。
ビューはNumPyの重要な概念です。NumPyの関数や、インデックス付けやスライスなどの操作は、可能な限りビューを返します。これによりメモリが節約され、処理速度も向上します(データのコピーを作成する必要がないため)。ただし、ビュー内のデータを変更すると元の配列も変更されることに注意してください。
例えば、次のような配列を作成するとします。
b1次に、スライスを使って配列を作成しa、の最初の要素を変更します b1。これにより、の対応する要素も変更されますa。
99, 2, 3, 4])
a
array(99, 2, 3, 4],
[ 5, 6, 7, 8],
[ 9, 10, 11, 12b1 = a[0, :]
b1
array([1, 2, 3, 4])
b1[0] = 99
b1
array([)
このcopyメソッドを使用すると、配列とそのデータの完全なコピー( ディープコピー)が作成されます。配列でこれを使用するには、次のように実行します。
b2 = a.copy()
基本的な配列操作
このセクションでは、足し算、引き算、掛け算、割り算などを扱います。
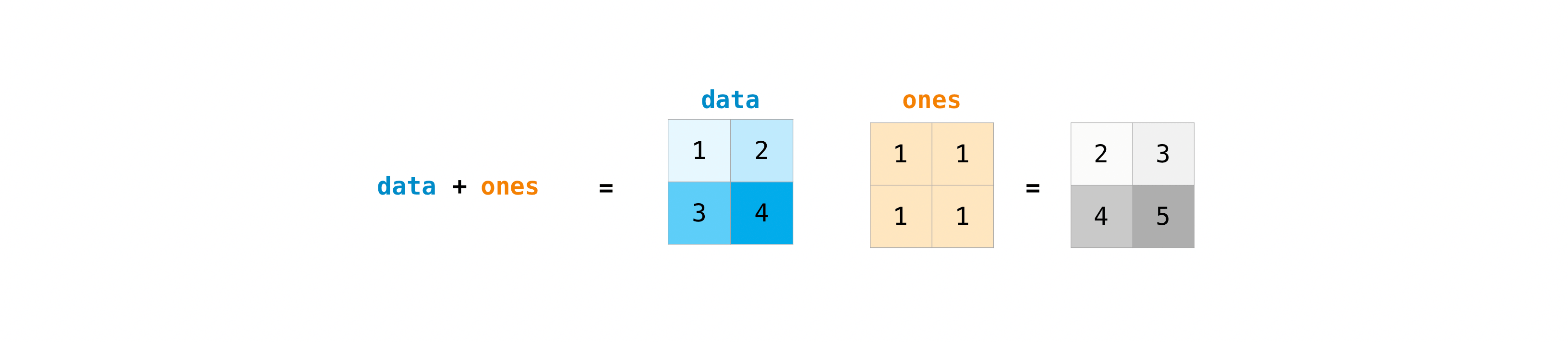
配列を作成したら、それらを使って作業を開始できます。たとえば、「data」と「ones」という名前の2つの配列を作成したとしましょう。
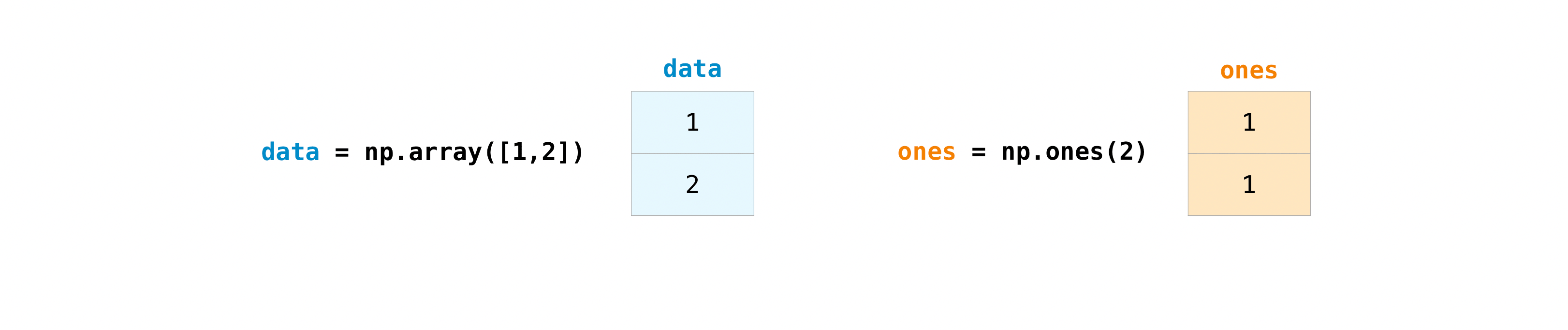
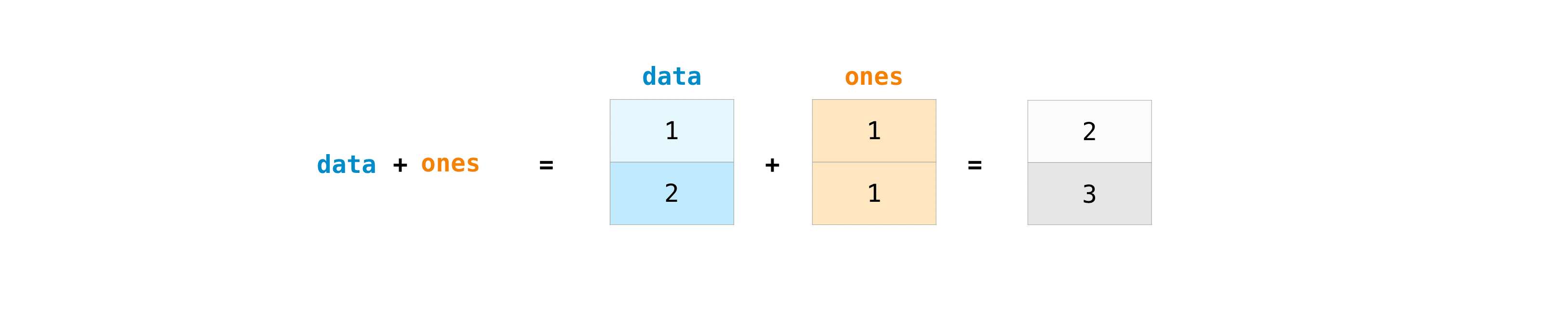
配列はプラス記号を使って足し合わせることができます。
data = np.array([1, 2])
ones = np.ones(2, dtype=int)
data + ones
array([2, 3])
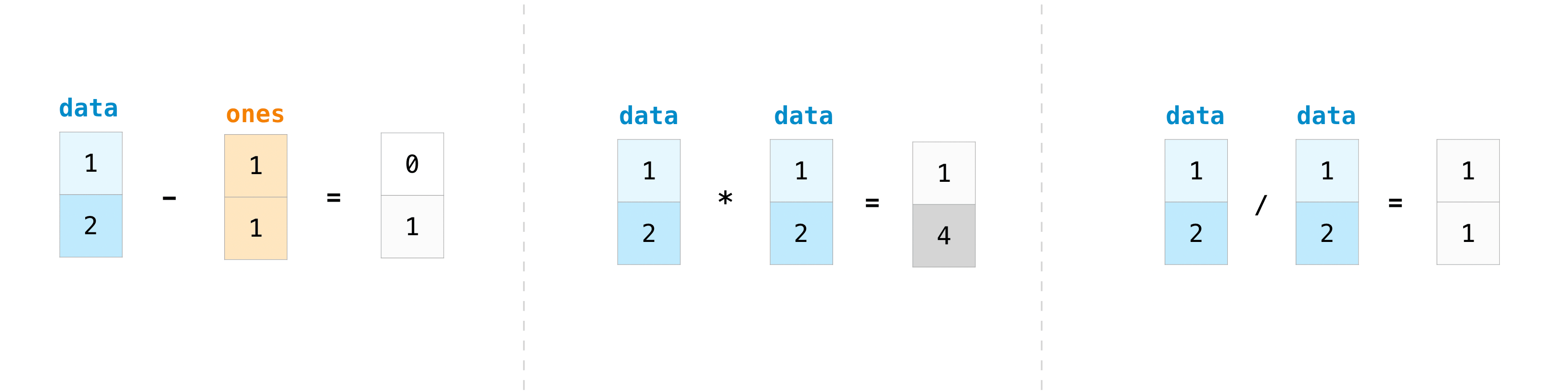
もちろん、足し算以外にもできることがありますよ!
data - ones
array([0, 1])
data * data
array([1, 4])
data / data
array([1., 1.])
NumPy では基本的な操作は簡単です。配列の要素の合計を求めるには、 を使用しますsum()。これは、1 次元配列、2 次元配列、およびそれ以上の次元の配列で機能します。
a = np.array([1, 2, 3, 4])
a.sum()
10
2次元配列の行または列を追加するには、軸を指定します。
この配列から始めるとします。
行軸に沿って合計を計算するには、次の方法を使用できます。
b.sum(axis=0)
array([3, 3])
列軸に沿って合計を計算するには、次の方法を使用できます。
b.sum(axis=1)
array([2, 4])
放送
配列と単一の数値(ベクトルとスカラー間の演算とも呼ばれます)の間、またはサイズの異なる2つの配列の間で演算を実行したい場合があります。たとえば、配列(ここでは「データ」と呼びます)にマイル単位の距離情報が含まれているが、その情報をキロメートルに変換したい場合などです。この演算は次のように実行できます。
data = np.array([1.0, 2.0])
data * 1.6
array([1.6, 3.2])
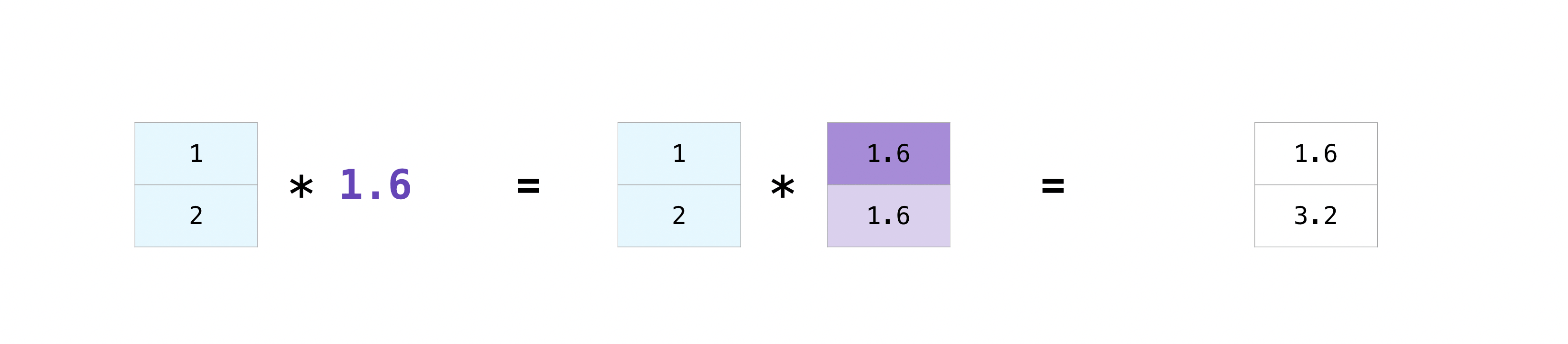
NumPy は、乗算が各セルで行われる必要があることを理解します。この概念はブロードキャストと呼ばれます。ブロードキャストは、NumPy が異なる形状の配列に対して演算を実行できるようにするメカニズムです。配列の次元は互換性がある必要があります。たとえば、両方の配列の次元が同じか、どちらか一方が 1 の場合などです。次元が互換性がない場合、エラーが発生しますValueError。
より便利な配列操作
このセクションでは、最大値、最小値、合計、平均、積、標準偏差などについて説明します。
minNumPyは集計関数も実行できます。 、、、に加えてmax、 平均を求める、要素を掛け合わせた結果を求める、標準偏差を求めるなど、さまざまなsum関数を簡単に実行できます。meanprodstd
data = np.array([1, 2, 3])
data.max()
3
data.min()
1
data.sum()
6
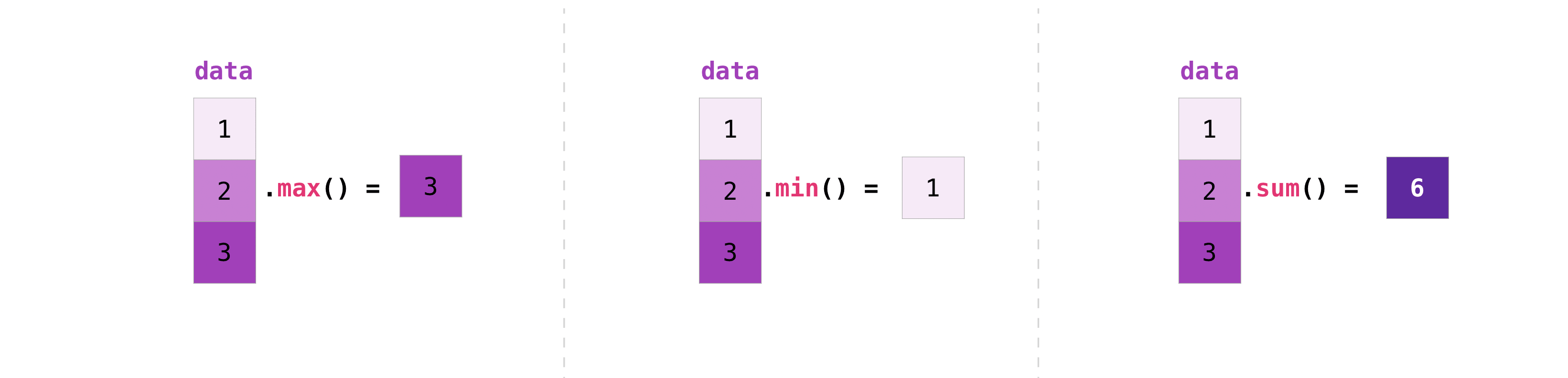
まずは「a」と呼ばれるこの配列から始めましょう。
行または列に沿って集計したい場合、非常によくあることです。デフォルトでは、すべての NumPy 集計関数は配列全体の集計値を返します。配列内の要素の合計または最小値を求めるには、次のコマンドを実行します。
a.sum()
4.8595784
または:
a.min()
0.05093587
集計関数を計算する軸を指定できます。たとえば、各列内の最小値を求めるには、 を指定します axis=0。
a.min(axis=0)
array([0.12697628, 0.05093587, 0.26590556, 0.5510652 ])
上記の4つの値は、配列の列数に対応しています。4列の配列の場合、結果として4つの値が得られます。
配列メソッドの詳細については、こちらをご覧ください。
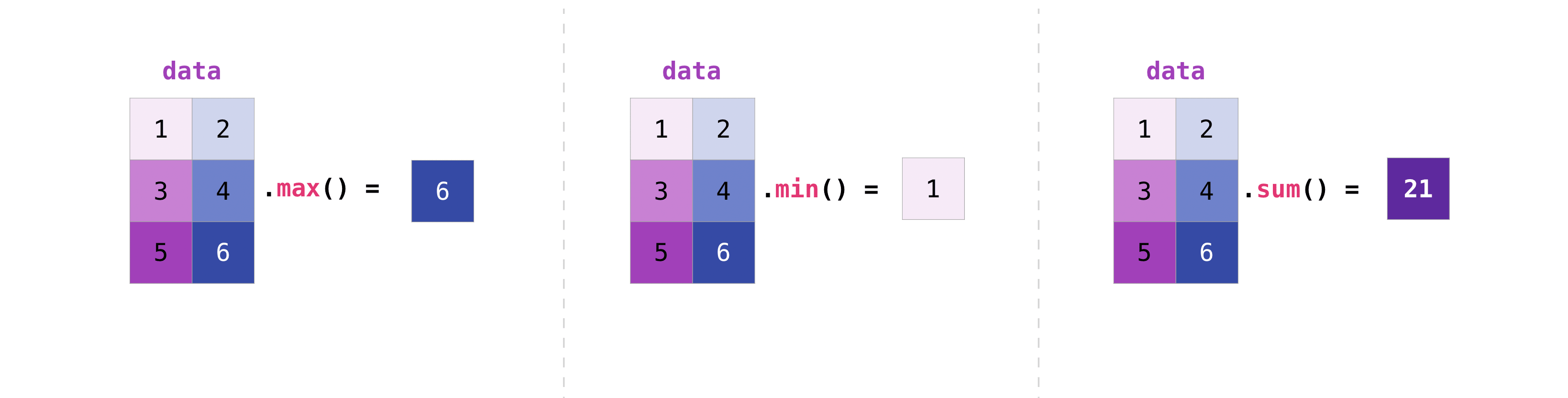
行列の作成
Pythonのリストのリストを渡すことで、NumPyでそれらを表現するための2次元配列(または「行列」)を作成できます。

インデックス付けとスライス操作は、行列を操作する際に役立ちます。

行列を集計する方法は、ベクトルを集計する方法と同じです。
data.max()
6
data.min()
1
data.sum()
21
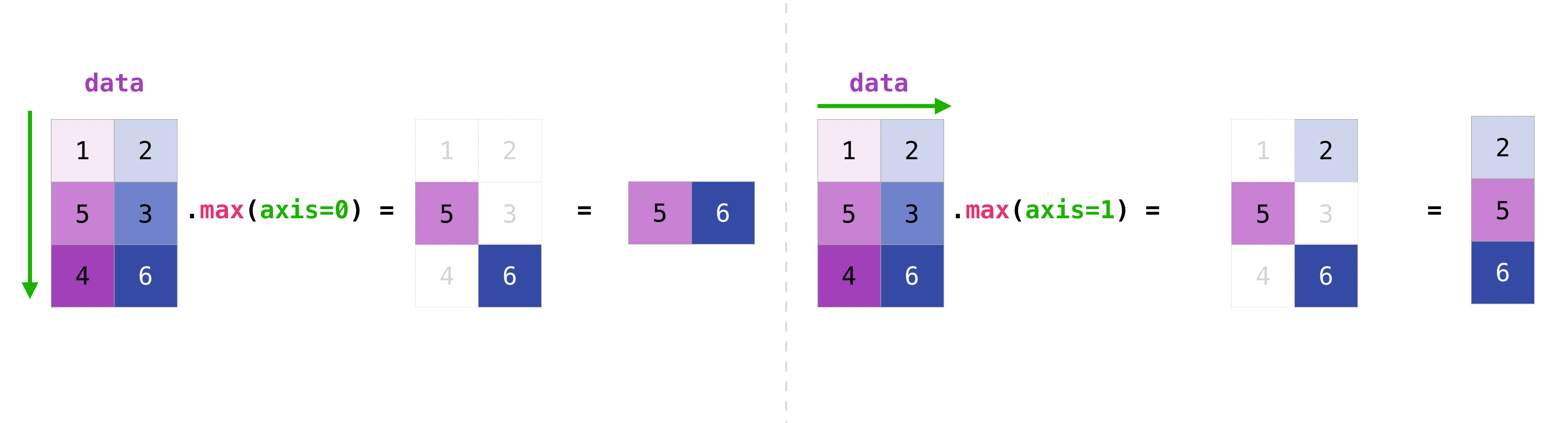
行列内のすべての値を集計することができ、axisパラメータを使用して列または行にわたって集計することもできます。この点を説明するために、少し変更したデータセットを見てみましょう。
data = np.array(1, 2], [5, 3], [4, 6)
data
array(1, 2],
[5, 3],
[4, 6)
data.max(axis=0)
array([5, 6])
data.max(axis=1)
array([2, 5, 6])
行列を作成したら、同じサイズの行列が2つある場合は、算術演算子を使用して加算と乗算を行うことができます。
これらの算術演算は、異なるサイズの行列に対しても実行できますが、それは行列の列または行が1つしかない場合に限ります。この場合、NumPyは演算にブロードキャスト規則を使用します。
data = np.array(1, 2], [3, 4], [5, 6)
ones_row = np.array(1, 1)
data + ones_row
array(2, 3],
[4, 5],
[6, 7)
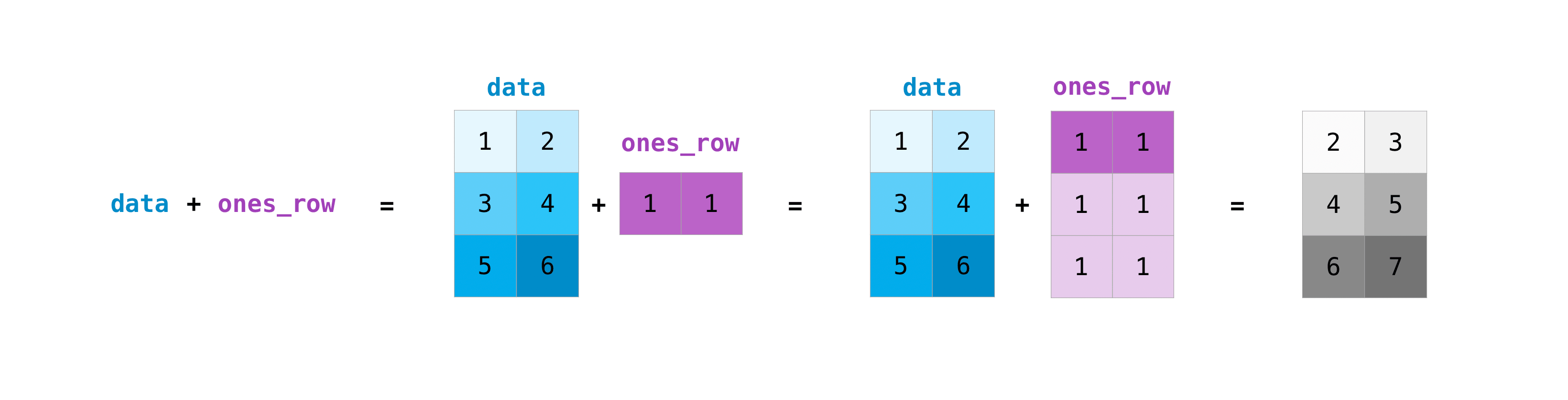
NumPyがN次元配列を出力する際、最後の軸が最も速くループされ、最初の軸が最も遅くループされることに注意してください。例:
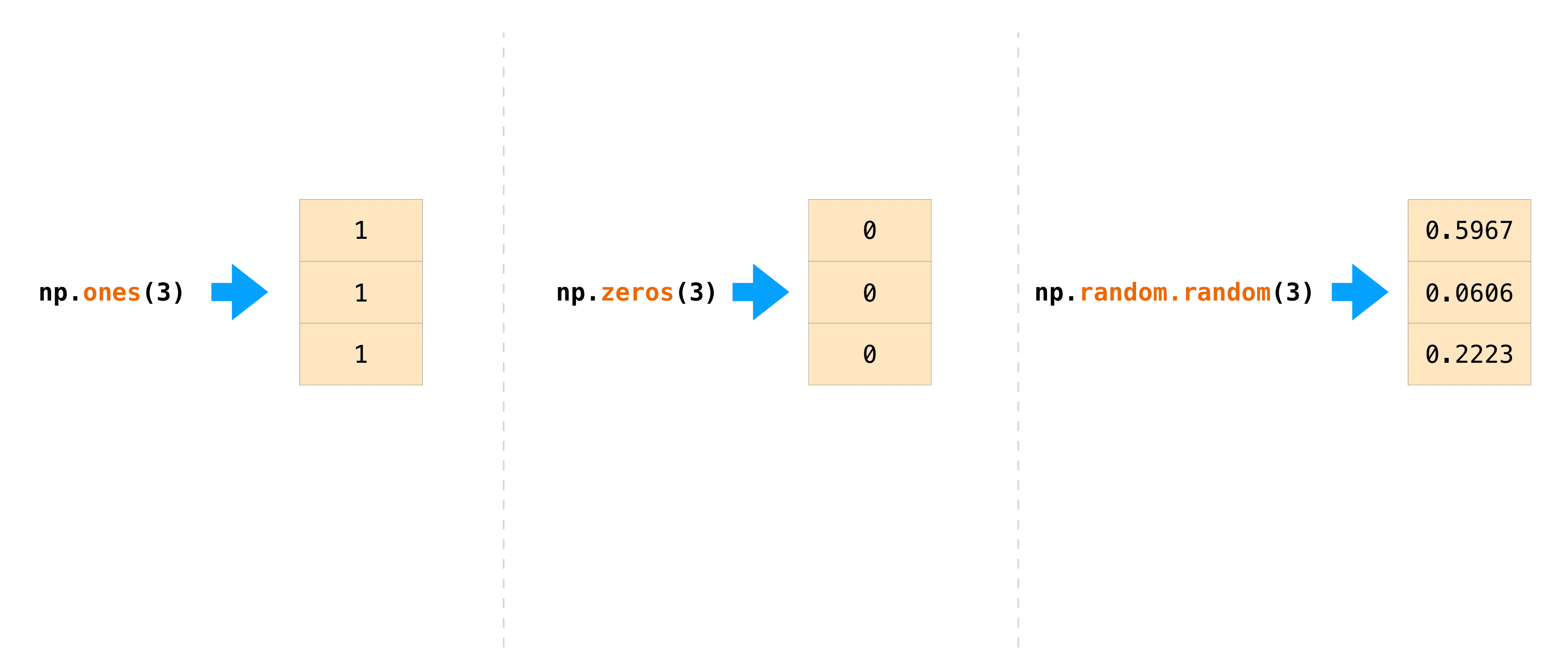
NumPyで配列の値を初期化したい場面はよくあります。NumPyには、といった関数ones()や、乱数生成のためのzeros()クラス が用意されていますrandom.Generator。必要なのは、生成したい要素の数を渡すだけです。
np.ones(3)
array([1., 1., 1.])
np.zeros(3)
array([0., 0., 0.])
rng = np.random.default_rng() # the simplest way to generate random numbers
rng.random(3)
array([0.63696169, 0.26978671, 0.04097352])
行列の次元を表すタプルを指定すればones()、 、zeros()、 を使って2次元配列を作成することもできます。random()
np.ones((3, 2))
array(1., 1.],
[1., 1.],
[1., 1.)
np.zeros((3, 2))
array(0., 0.],
[0., 0.],
[0., 0.)
rng.random((3, 2))
array(0.01652764, 0.81327024],
[0.91275558, 0.60663578],
[0.72949656, 0.54362499) # may vary

配列の作成、配列に0'、1'、その他の値、または初期化されていない値を格納する方法については、配列作成ルーチンを参照してください。
乱数を生成中
乱数生成は、多くの数値アルゴリズムや機械学習アルゴリズムの設定および評価において重要な要素です。人工ニューラルネットワークの重みをランダムに初期化したり、データをランダムなセットに分割したり、データセットをランダムにシャッフルしたりする必要がある場合、乱数(正確には、再現可能な擬似乱数)を生成できることは不可欠です。
を使用するとGenerator.integers、小さい値(NumPyでは小さい値を含むことに注意してください)から大きい値(小さい値を含まない)までの乱数を生成できます。 を設定する endpoint=Trueと、大きい値を含むようになります。
0から4までのランダムな整数からなる2×4の配列は、以下の方法で生成できます。
ユニークなアイテムとカウントを取得する方法
このセクションでは、 np.unique()
配列内の固有要素は、 を使って簡単に見つけることができますnp.unique。
例えば、次のような配列から始めるとします。
a = np.array([11, 11, 12, 13, 14, 15, 16, 17, 12, 13, 11, 14, 18, 19, 20])
np.unique配列内の一意の値を出力するには、以下を使用できます。
unique_values = np.unique(a)
print(unique_values)
[11 12 13 14 15 16 17 18 19 20]
NumPy配列内の一意の値のインデックス(配列内の一意の値の最初のインデックス位置の配列)を取得するには、return_index 引数np.unique()と配列を渡すだけです。
unique_values, indices_list = np.unique(a, return_index=True)
print(indices_list)
[ 0 2 3 4 5 6 7 12 13 14]
NumPy配列内の固有値の出現頻度を取得するには、return_counts引数を配列と一緒に渡すことができます。np.unique()
unique_values, occurrence_count = np.unique(a, return_counts=True)
print(occurrence_count)
[3 2 2 2 1 1 1 1 1 1]
これは2次元配列でも機能します!この配列から始めるとします。
以下の方法で独自の値を見つけることができます。
unique_values = np.unique(a_2d)
print(unique_values)
[ 1 2 3 4 5 6 7 8 9 10 11 12]
axis引数が渡されない場合、2次元配列は平坦化されます。
一意の行または列を取得する場合は、axis 引数を渡すようにしてください。一意の行を検索するには、 を指定しaxis=0、列を検索するには、 を指定します axis=1。
一意の行、インデックス位置、出現回数を取得するには、以下を使用できます。
unique_rows, indices, occurrence_count = np.unique(
a_2d, axis=0, return_counts=True, return_index=True)
print(unique_rows)
1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12
print(indices)
[0 1 2]
print(occurrence_count)
[2 1 1]
配列内の固有要素を見つける方法について詳しくは、を参照してくださいunique。
行列の転置と再形成
このセクションでは arr.reshape()、、、について説明しますarr.transpose()。arr.T
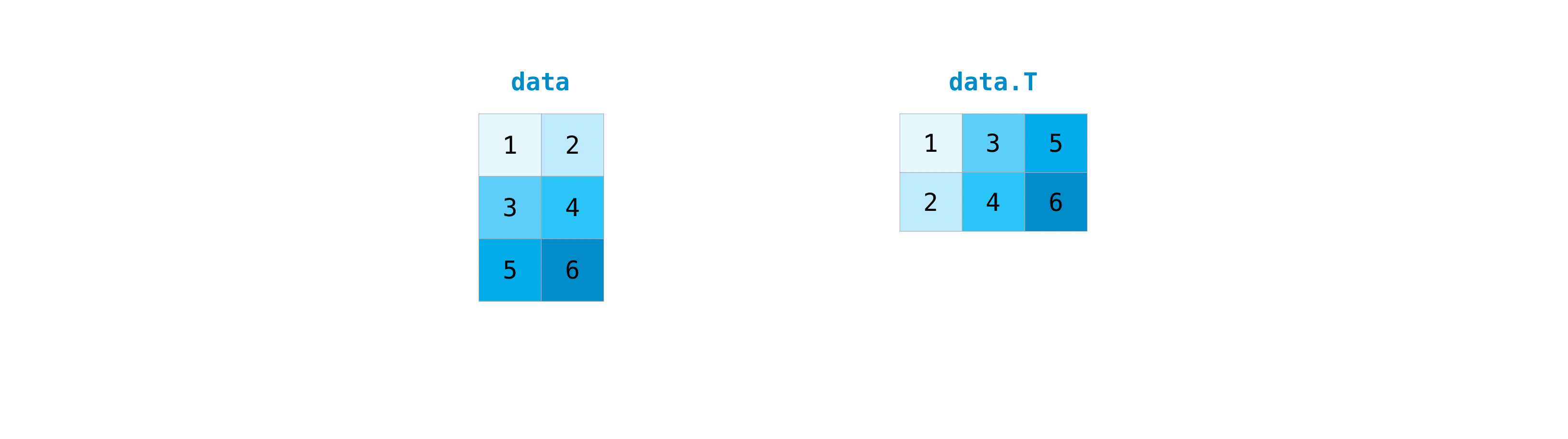
行列を転置する必要があることはよくあります。NumPy配列には、 T行列を転置できる機能が備わっています。
行列の次元を変更する必要が生じる場合もあります。これは、例えば、モデルがデータセットとは異なる特定の入力形状を想定している場合などに発生します。このような場合に、このreshapeメソッドが役立ちます。行列に適用したい新しい次元を渡すだけで済みます。
.transpose()また、指定した値に応じて配列の軸を反転または変更するためにも使用できます。
この配列から始めるとします。
配列は で転置できますarr.transpose()。
次のようにも使用できますarr.T。
配列を反転する方法
このセクションでは、 np.flip()
NumPyのnp.flip()関数を使用すると、配列の内容を軸に沿って反転(反転)させることができます。この関数を使用する際はnp.flip()、反転させたい配列と軸を指定してください。軸を指定しない場合、NumPyは入力配列のすべての軸に沿って内容を反転させます。
1次元配列を反転する
次のような1次元配列から始める場合:
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
逆算するには、以下を使用してください。
reversed_arr = np.flip(arr)
逆順の配列を印刷したい場合は、次のコマンドを実行してください。
print('Reversed Array: ', reversed_arr)
Reversed Array: [8 7 6 5 4 3 2 1]
2次元配列を反転する
2次元配列もほぼ同じように機能します。
この配列から始めるとします。
すべての行とすべての列の内容を反転するには、次の操作を行います。
以下の方法で行だけを簡単に反転できます。
または、列のみを反転させるには、次のようにします。
reversed_arr_columns = np.flip(arr_2d, axis=1)
print(reversed_arr_columns)
4 3 2 1]
[ 8 7 6 5]
[12 11 10 9
1つの列または行の内容だけを反転させることもできます。たとえば、インデックス位置1(2行目)の行の内容を反転させることができます。
インデックス位置1(2列目)の列を反転させることもできます。
配列の反転に関する詳細は、こちらをご覧くださいflip。
多次元配列の形状変更と平坦化
このセクションでは .flatten()、ravel()
配列をフラット化する一般的な方法は 2 つあります。.flatten()と です.ravel()。この 2 つの主な違いは、 を使用して作成される新しい配列は、 ravel()実際には親配列への参照 (つまり「ビュー」) であるということです。つまり、新しい配列への変更は親配列にも影響します。 はravelコピーを作成しないため、メモリ効率に優れています。
この配列から始めるとします。
flatten配列を1次元配列に平坦化するために使用できます。
x.flatten()
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
を使用するとflatten、新しい配列への変更は親配列には影響しません。
例えば:
0] = 99
print(x) # Original array
1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12a1 = x.flatten()
a1[
print(a1) # New array
[99 2 3 4 5 6 7 8 9 10 11 12]
しかし、を使用するとravel、新しい配列に加えた変更は親配列にも影響します。
例えば:
0] = 98
print(x) # Original array
98 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12a2 = x.ravel()
a2[
print(a2) # New array
[98 2 3 4 5 6 7 8 9 10 11 12]
flattenとについての詳細は、ndarray.flattenこちらravelをご覧くださいravel。
ドキュメント文字列にアクセスして詳細情報を確認する方法
このセクションでは help()、、、について説明します?。??
データサイエンスのエコシステムにおいて、PythonとNumPyはユーザーを念頭に置いて設計されています。その最たる例の一つが、ドキュメントへの組み込みアクセスです。すべてのオブジェクトには、ドキュメント文字列と呼ばれる文字列への参照が含まれています。ほとんどの場合、このドキュメント文字列には、オブジェクトの概要と使用方法が簡潔にまとめられています。Pythonには、help() この情報にアクセスできる組み込み関数があります。つまり、より詳しい情報が必要なときはいつでも、この関数を使ってhelp()必要な情報を素早く見つけることができるのです。
例えば:
help(max)
Help on built-in function max in module builtins:
max(...)
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
追加情報へのアクセスは非常に便利なため、IPython では、? このドキュメントやその他の関連情報にアクセスするためのショートカットとして文字を使用します。IPython は、複数の言語で対話型コンピューティングを行うためのコマンドシェルです。IPython の詳細については、こちらをご覧ください。
例えば:
max?
max(iterable, *[, default=obj, key=func]) -> value
max(arg1, arg2, *args, *[, key=func]) -> value
With a single iterable argument, return its biggest item. The
default keyword-only argument specifies an object to return if
the provided iterable is empty.
With two or more arguments, return the largest argument.
Type: builtin_function_or_method
この表記法は、オブジェクトのメソッドやオブジェクト自体にも使用できます。
例えば、次のような配列を作成するとします。
a = np.array([1, 2, 3, 4, 5, 6])
すると、多くの有用な情報(まずa自身に関する詳細情報、次にインスタンスでndarrayあるもののドキュメント文字列)を取得できます。a
a?
Type: ndarray
String form: [1 2 3 4 5 6]
Length: 6
File: ~/anaconda3/lib/python3.9/site-packages/numpy/__init__.py
Docstring: <no docstring>
Class docstring:
ndarray(shape, dtype=float, buffer=None, offset=0,
strides=None, order=None)
An array object represents a multidimensional, homogeneous array
of fixed-size items. An associated data-type object describes the
format of each element in the array (its byte-order, how many bytes it
occupies in memory, whether it is an integer, a floating point number,
or something else, etc.)
Arrays should be constructed using `array`, `zeros` or `empty` (refer
to the See Also section below). The parameters given here refer to
a low-level method (`ndarray(...)`) for instantiating an array.
For more information, refer to the `numpy` module and examine the
methods and attributes of an array.
Parameters
----------
(for the __new__ method; see Notes below)
shape : tuple of ints
Shape of created array.
...
これは、作成した関数やその他のオブジェクトにも適用できます。関数には文字列リテラルを使用してドキュメント文字列を含めるか、ドキュメントの周囲に記述することを忘れないでください。""" """''' '''
例えば、次のような関数を作成するとします。
def double(a):
'''Return a * 2'''
return a * 2
機能に関する情報は以下から入手できます。
double?
Signature: double(a)
Docstring: Return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
関心のあるオブジェクトのソースコードを読むことで、さらに詳細な情報を得ることができます。二重疑問符(??)を使用すると、ソースコードにアクセスできます。
例えば:
double??
Signature: double(a)
Source:
def double(a):
'''Return a * 2'''
return a * 2
File: ~/Desktop/<ipython-input-23-b5adf20be596>
Type: function
対象のオブジェクトが Python 以外の言語でコンパイルされている場合、を使用すると、 ??と同じ情報が返されます?。これは、多くの組み込みオブジェクトや型で見られます。たとえば、次のようになります。
len?
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
そして :
len??
Signature: len(obj, /)
Docstring: Return the number of items in a container.
Type: builtin_function_or_method
これらはPython以外のプログラミング言語でコンパイルされているため、同じ出力になります。
数式を使った作業
配列を扱う数式を簡単に実装できることは、NumPyが科学計算を行うPythonコミュニティで広く使われている理由の一つです。
例えば、これは平均二乗誤差の公式です(回帰を扱う教師あり機械学習モデルで用いられる中心的な公式です)。
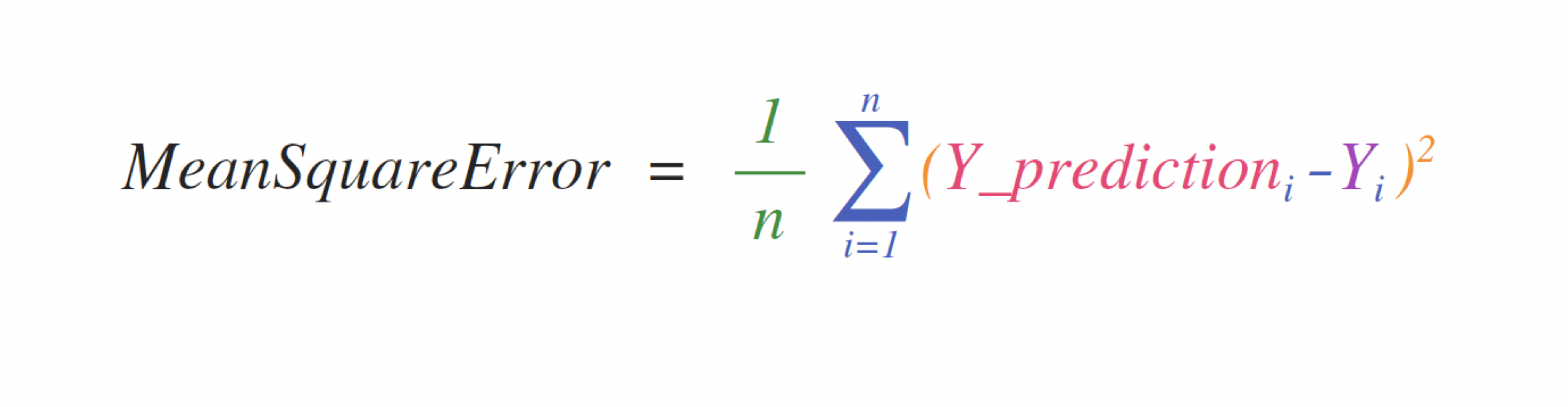
この数式をNumPyで実装するのは簡単かつ分かりやすいです。
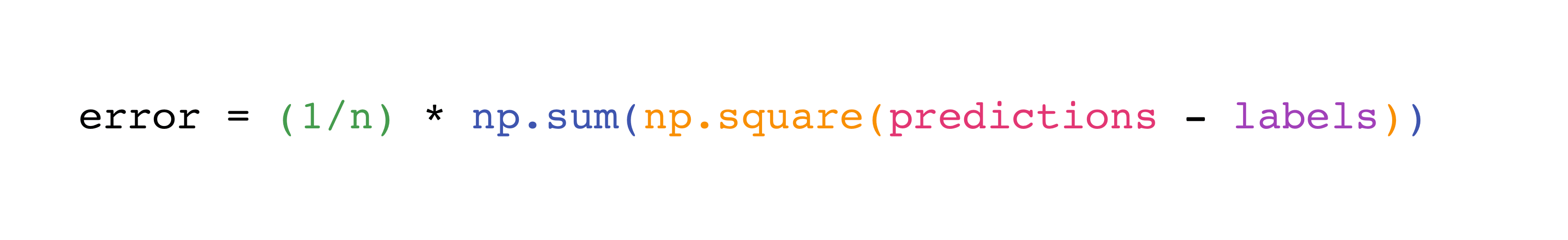
この仕組みがうまく機能する理由は、predictionsとがlabels1つでも1000個でも値を格納できるからです。必要なのは、それらの値のサイズが同じであることだけです。
次のようにイメージできます。

この例では、予測ベクトルとラベルベクトルの両方に3つの値が含まれているため、n値は3になります。減算を実行した後、ベクトル内の値は2乗されます。次に、NumPyが値を合計し、その結果がその予測のエラー値とモデルの品質スコアになります。

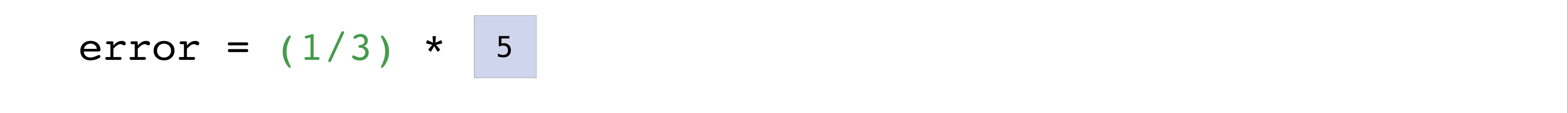
NumPyオブジェクトの保存と読み込み方法
このセクションでは 、、、、、np.saveについてnp.savez説明しますnp.savetxt。 np.loadnp.loadtxt
いずれかの時点で、配列をディスクに保存し、コードを再実行せずにディスクから読み込みたい場合があります。幸いなことに、NumPy ではオブジェクトを保存および読み込むための方法がいくつかあります。ndarray オブジェクトは、通常のテキスト ファイルを処理する関数、.npyファイル拡張子を持つ NumPy バイナリ ファイルを処理する関数、および.npzファイル拡張子を持つ NumPy ファイルを処理する関数を使用して、ディスク ファイルに保存およびディスクから読み込むことがloadtxtできます。savetxtloadsavesavez
.npyファイルと.npzファイルには、ndarray を再構築するために必要なデータ、形状、dtype、およびその他の情報が格納されており、ファイルがアーキテクチャの異なる別のマシン上にある場合でも、配列を正しく取得できるようになっています。
単一の ndarray オブジェクトを保存する場合は、.npy ファイルとして保存します np.save。 複数の ndarray オブジェクトを単一のファイルに保存する場合は、.npz ファイルとして保存しますnp.savez。 また、複数の配列を圧縮 npz 形式で単一のファイルに保存することもできますsavez_compressed。
配列の保存と読み込みは簡単ですnp.save()。保存したい配列とファイル名を指定するだけです。たとえば、次のような配列を作成した場合:
a = np.array([1, 2, 3, 4, 5, 6])
次のようにして「filename.npy」として保存できます。
np.save('filename', a)
np.load()配列を再構築するために使用できます。
b = np.load('filename.npy')
配列を確認したい場合は、以下を実行してください。
print(b)
[1 2 3 4 5 6]
NumPy配列は、 .csvや.txtファイルのようなプレーンテキストファイルとして保存できますnp.savetxt。
例えば、次のような配列を作成する場合:
csv_arr = np.array([1, 2, 3, 4, 5, 6, 7, 8])
次のようにして、「new_file.csv」という名前で簡単に.csvファイルとして保存できます。
np.savetxt('new_file.csv', csv_arr)
保存したテキストファイルをすばやく簡単に読み込むには、以下を使用してくださいloadtxt()。
np.loadtxt('new_file.csv')
array([1., 2., 3., 4., 5., 6., 7., 8.])
および関数savetxt()はloadtxt()、ヘッダー、フッター、区切り文字などの追加のオプションパラメータを受け入れます。テキストファイルは共有しやすいですが、.npy および .npz ファイルはサイズが小さく、読み込みが高速です。テキストファイルのより高度な処理が必要な場合 (たとえば、欠損値を含む行を処理する必要がある場合) は、関数を使用する必要がありますgenfromtxt 。
を使用するとsavetxt、ヘッダー、フッター、コメントなどを指定できます。
入出力ルーチンについての詳細は、こちらをご覧ください。
CSVファイルのインポートとエクスポート
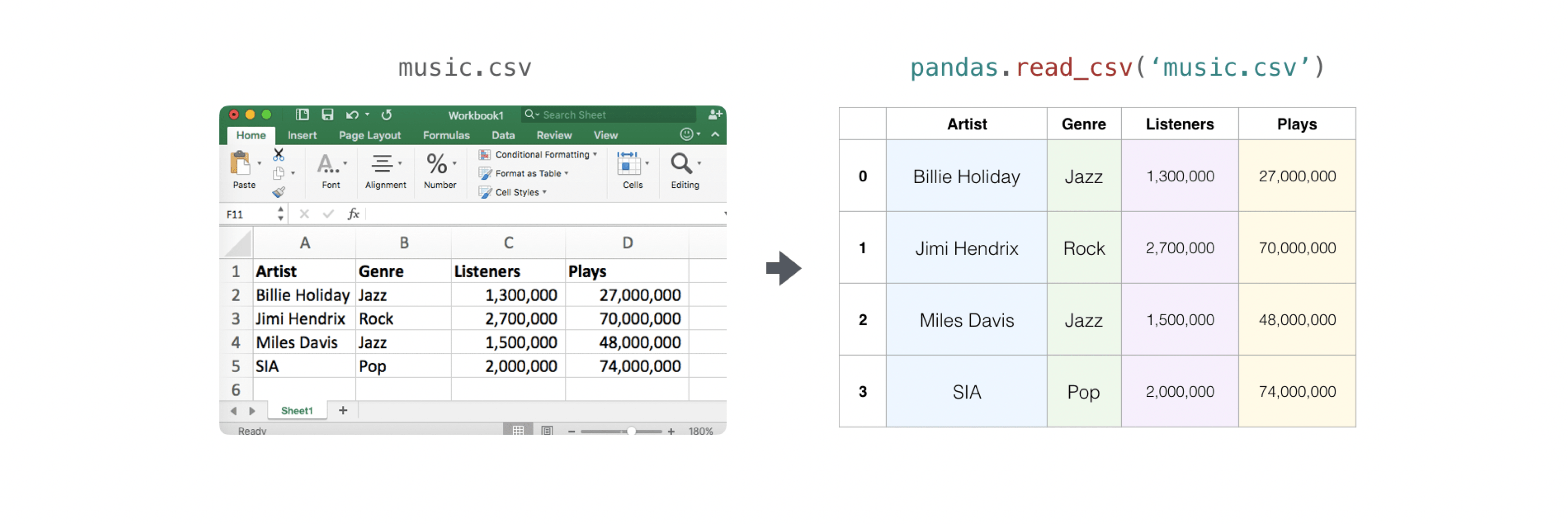
既存の情報を含むCSVファイルを読み込むのは簡単です。これを行うための最良かつ最も簡単な方法は、 Pandasを使用することです。
import pandas as pd
# If all of your columns are the same type:
x = pd.read_csv('music.csv', header=0).values
print(x)
'Billie Holiday' 'Jazz' 1300000 27000000]
['Jimmie Hendrix' 'Rock' 2700000 70000000]
['Miles Davis' 'Jazz' 1500000 48000000]
['SIA' 'Pop' 2000000 74000000'Artist', 'Plays']).values
print(x)
'Billie Holiday' 27000000]
['Jimmie Hendrix' 70000000]
['Miles Davis' 48000000]
['SIA' 74000000
# You can also simply select the columns you need:
x = pd.read_csv('music.csv', usecols=[
Pandasを使えば、配列をエクスポートするのも簡単です。NumPyを初めて使う場合は、配列の値からPandasデータフレームを作成し、そのデータフレームをPandasでCSVファイルに書き込むと良いでしょう。
この配列「a」を作成した場合
Pandasデータフレームを作成できます
df = pd.DataFrame(a)
print(df)
0 1 2 3
0 -2.582892 0.430148 -1.240820 1.595726
1 0.990278 1.171510 0.941257 -0.146925
2 0.769893 0.812997 -0.950684 0.117696
3 0.204840 0.347845 1.969792 0.519928
データフレームは、以下の方法で簡単に保存できます。
df.to_csv('pd.csv')
CSVファイルを読み込むには、以下のコマンドを使用します。
data = pd.read_csv('pd.csv')

NumPy メソッドを使用して配列を保存することもできますsavetxt。
np.savetxt('np.csv', a, fmt='%.2f', delimiter=',', header='1, 2, 3, 4')
コマンドラインを使用している場合は、次のようなコマンドを使用して、保存した CSV をいつでも読み取ることができます。
$ cat np.csv
# 1, 2, 3, 4
-2.58,0.43,-1.24,1.60
0.99,1.17,0.94,-0.15
0.77,0.81,-0.95,0.12
0.20,0.35,1.97,0.52
または、テキスト エディターを使用していつでもファイルを開くことができます。
Pandasについてさらに詳しく知りたい場合は、公式のPandasドキュメントをご覧ください 。公式のPandasインストール情報でPandasのインストール方法を学びましょう 。
Matplotlib で配列をプロットする
値のプロットを生成する必要がある場合は、 Matplotlibを使用すると非常に簡単にできます。
たとえば、次のような配列があるとします。
a = np.array([2, 1, 5, 7, 4, 6, 8, 14, 10, 9, 18, 20, 22])
Matplotlib がすでにインストールされている場合は、次のコマンドでインポートできます。
import matplotlib.pyplot as plt
# If you're using Jupyter Notebook, you may also want to run the following
# line of code to display your code in the notebook:
%matplotlib inline
値をプロットするために必要なのは、次のコマンドを実行することだけです。
plt.plot(a)
# If you are running from a command line, you may need to do this:
# >>> plt.show()
たとえば、次のように 1D 配列をプロットできます。
x = np.linspace(0, 5, 20)
y = np.linspace(0, 10, 20)
plt.plot(x, y, 'purple') # line
plt.plot(x, y, 'o') # dots
Matplotlib を使用すると、膨大な数の視覚化オプションにアクセスできます。
fig = plt.figure()
ax = fig.add_subplot(projection='3d')
X = np.arange(-5, 5, 0.15)
Y = np.arange(-5, 5, 0.15)
X, Y = np.meshgrid(X, Y)
R = np.sqrt(X**2 + Y**2)
Z = np.sin(R)
ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis')
Matplotlibとその機能について詳しく知りたい場合は、 公式ドキュメントをご覧ください。Matplotlibのインストール手順については、公式 インストールセクションをご覧ください。
画像クレジット: Jay Alammar https://jalammar.github.io/





コメント
最新を表示する
NG表示方式
NGID一覧